کشف گلوگاههای فرایند با پایتون و تحلیل دادهها

مقدمه: قاتلان پنهان بهرهوری
در دنیای پرشتاب امروز، شناسایی و رفع گلوگاهها (Bottlenecks) در فرایندهای سازمانی و صنعتی دیگر یک انتخاب نیست؛ یک ضرورت است. گلوگاهها مانند یک سد نامرئی عمل میکنند و سرعت جریان کار را کاهش میدهند، هزینهها را افزایش میدهند و در نهایت رضایت مشتری را تحت تأثیر قرار میدهند. در این مقاله، با استفاده از پایتون و تحلیل داده یاد میگیریم چگونه این نقاط محدودکننده را شناسایی کنیم.
گلوگاه چیست؟
فرض کنید یک خط تولید شامل ۱۰ دستگاه باشد: ۹ دستگاه در هر ساعت ۱۰۰ قطعه تولید میکنند و ۱ دستگاه فقط ۵۰ قطعه تولید میکند، واضح است که کل سیستم نمیتواند بیش از ۵۰ قطعه در ساعت خروجی داشته باشد و همان دستگاه ۵۰ تایی، گلوگاه سیستم است، یعنی خروجی کل سیستم برابر است با ظرفیت محدودکنندهترین مرحله.
دادههای مورد استفاده در تحلیل
برای این تحلیل از یک مجموعهداده مصنوعی (شبیهسازیشده) به شرح زیر استفاده شده است: ۵ مرحله فرایند - ۱۰۰۰ رکورد
مرحله: دریافت>بررسی>پردازش>تایید>تحویل
زمان چرخه: میانگین زمان انجام کار در آن مرحله
زمان انتظار: زمان انتظار پیش از ورود به مرحله
کار در جریان: تعداد کارهای در جریان یا صف
نرخ خروجی: تعداد واحد خروجی در ساعت

این دادهها تولید شدهاند تا رفتار واقعی یک سیستم عملیاتی را شبیهسازی کنند.
معیارهای کلیدی برای شناسایی گلوگاه
برای تشخیص گلوگاه، چند شاخص مهم بررسی میشود:
زمان چرخه بالا: اگر مدتزمان انجام کار در یک مرحله زیاد باشد، احتمال گلوگاه بودن آن بالا میرود.
زمان انتظار بالا: اگر کارها قبل از ورود به یک مرحله زمان زیادی منتظر بمانند، آن مرحله احتمالاً توان پردازشی کافی ندارد.
کار در جریان بالا: تجمع کار در صف معمولاً نشانهای از محدودیت ظرفیت است.
نرخ خروجی پایین: مرحلهای که کمترین خروجی را دارد، کاندیدای اصلی گلوگاه است.
چرا از تشخیص ناهنجاری استفاده کنیم؟
در بسیاری از موارد، گلوگاهها باعث ایجاد دادههای غیرعادی میشوند:
- زمانهای چرخه غیرمعمول
- افزایش ناگهانی کار در جریان
- کاهش شدید نرخ خروجی
یکی از الگوریتمهای قدرتمند برای این کار Isolation Forest است که برای شناسایی نقاط پرت در دادههای چندبعدی بسیار مناسب است و نیاز به برچسبگذاری قبلی ندارد.
با پیادهسازی داده در پایتون می توان:
- میانگین عملکرد هر مرحله را مشاهده کرد.
- مراحل دارای زمانهای غیرعادی را شناسایی کرد.
- مرحلهای که بیشترین تعداد ناهنجاری را دارد مشخص کرد.
- مرحلهای که کمترین نرخ خروجی را دارد پیدا کرد.
ترکیب این شاخصها معمولاً گلوگاه واقعی را مشخص میکند.
جمعبندی
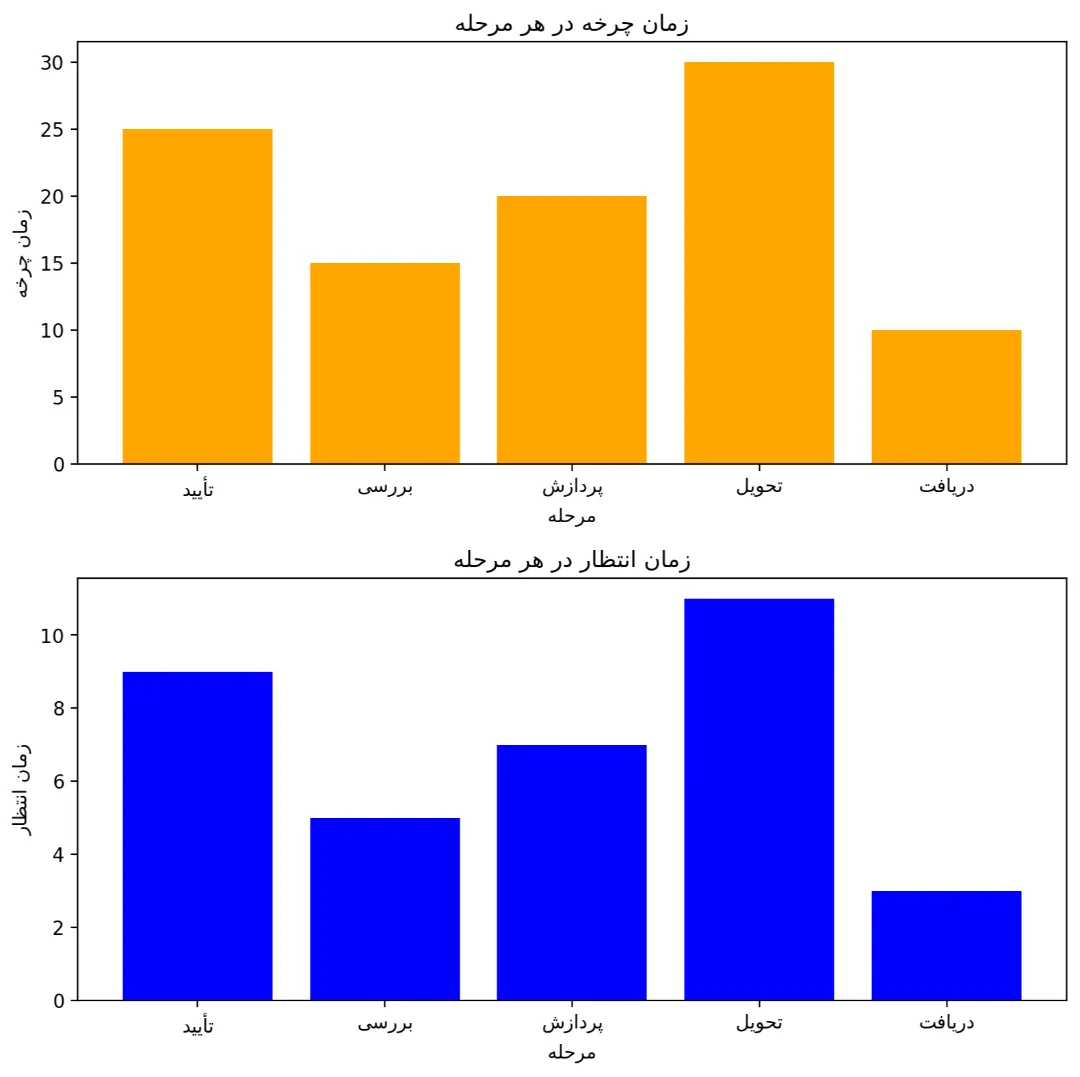
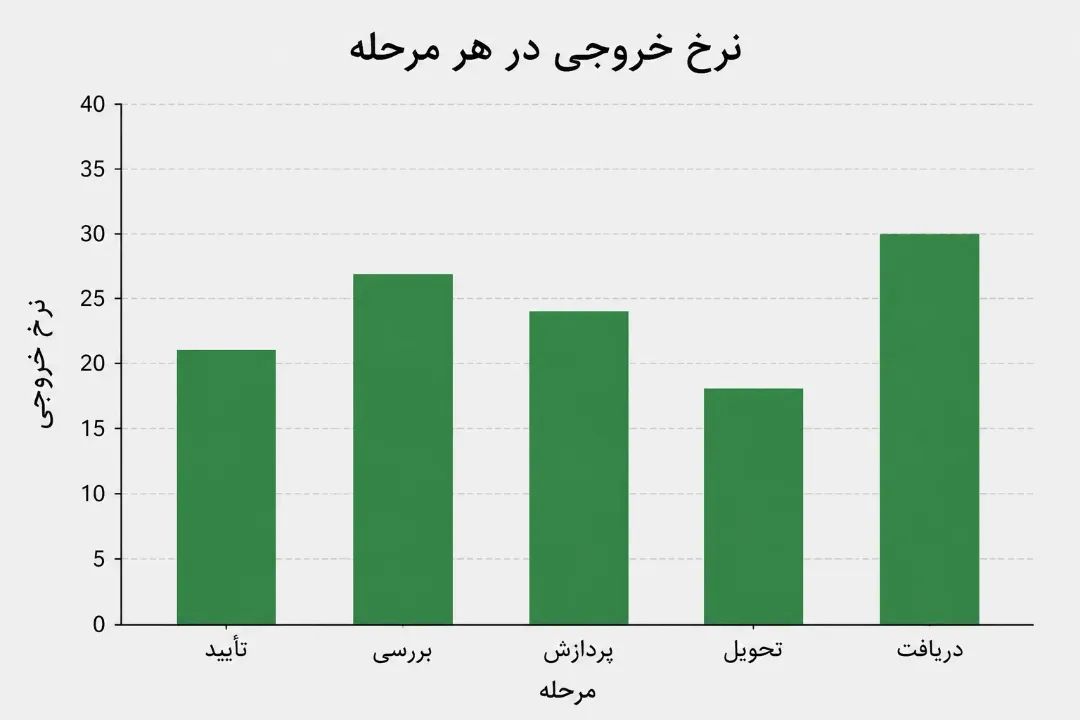
همان طور که در تصویر بالا نشان داده میشود مرحلهی "تحویل" زمان چرخه و زمان انتظار بالاتری دارد و به عنوان گلوگاه شناسایی شده است و این گلوگاه نرخ خروجی کمتری نیز دارد که در تصویر زیر مشخص شده است:
بنابراین با استفاده از تحلیل داده و پایتون تحلیل گلوگاه دیگر یک حدس تجربی نیست؛ یک مسئله تحلیلی و دادهمحور است.
✍ وجیهه واعظی نژاد






